Unsupervised Learning of Camera Pose with Compositional Re-estimation
 Saliency (static) models vs. Saccadic models
Saliency (static) models vs. Saccadic models
Abstract
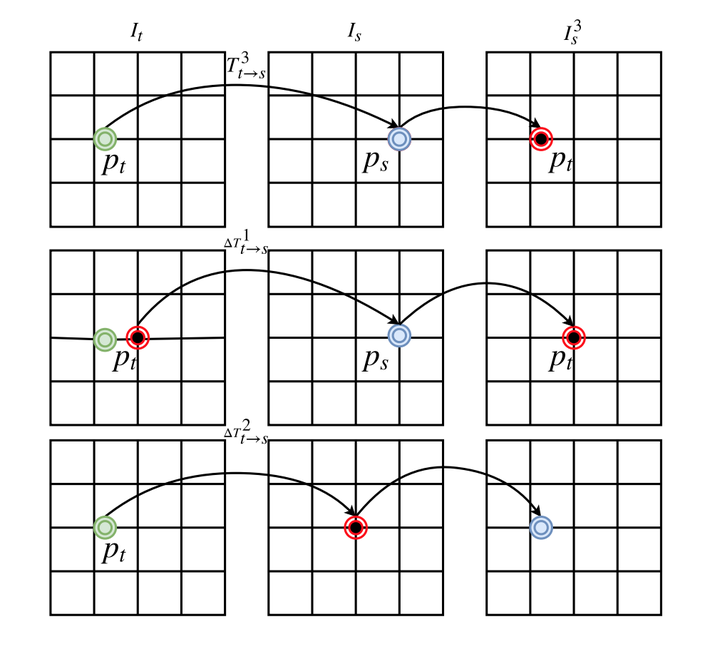
We consider the problem of unsupervised camera pose estimation. Given an input video sequence, our goal is to estimate the camera pose (i.e. the camera motion) between consecutive frames. Traditionally, this problem is tackled by placing strict constraints on the transformation vector or by incorporating optical flow through a complex pipeline. We propose an alternative approach that utilizes a compositional re-estimation process for camera pose estimation. Given an input, we first estimate a depth map. Our method then iteratively estimates the camera motion based on the estimated depth map. Our approach significantly improves the predicted camera motion both quantitatively and visually. Furthermore, the re-estimation resolves the problem of out-of-boundaries pixels in a novel and simple way. Another advantage of our approach is that it is adaptable to other camera pose estimation approaches. Experimental analysis on KITTI benchmark dataset demonstrates that our method outperforms existing state-of-the-art approaches in unsupervised camera ego-motion estimation.